AI bots power some of the most advanced technologies we use today, from search engines to AI assistants. However, their increasing presence has led to a growing number of websites blocking them.
There’s a cost to bots crawling your websites and there’s a social contract between search engines and website owners, where search engines add value by sending referral traffic to websites. This is what keeps most websites from blocking search engines like Google, even as Google seems intent on taking more of that traffic for themselves. This social contract extends to generative engines.
When we looked at the traffic makeup of ~35K websites in Ahrefs Analytics, we found that AI sends just 0.1% of total referral traffic—far behind that of search.
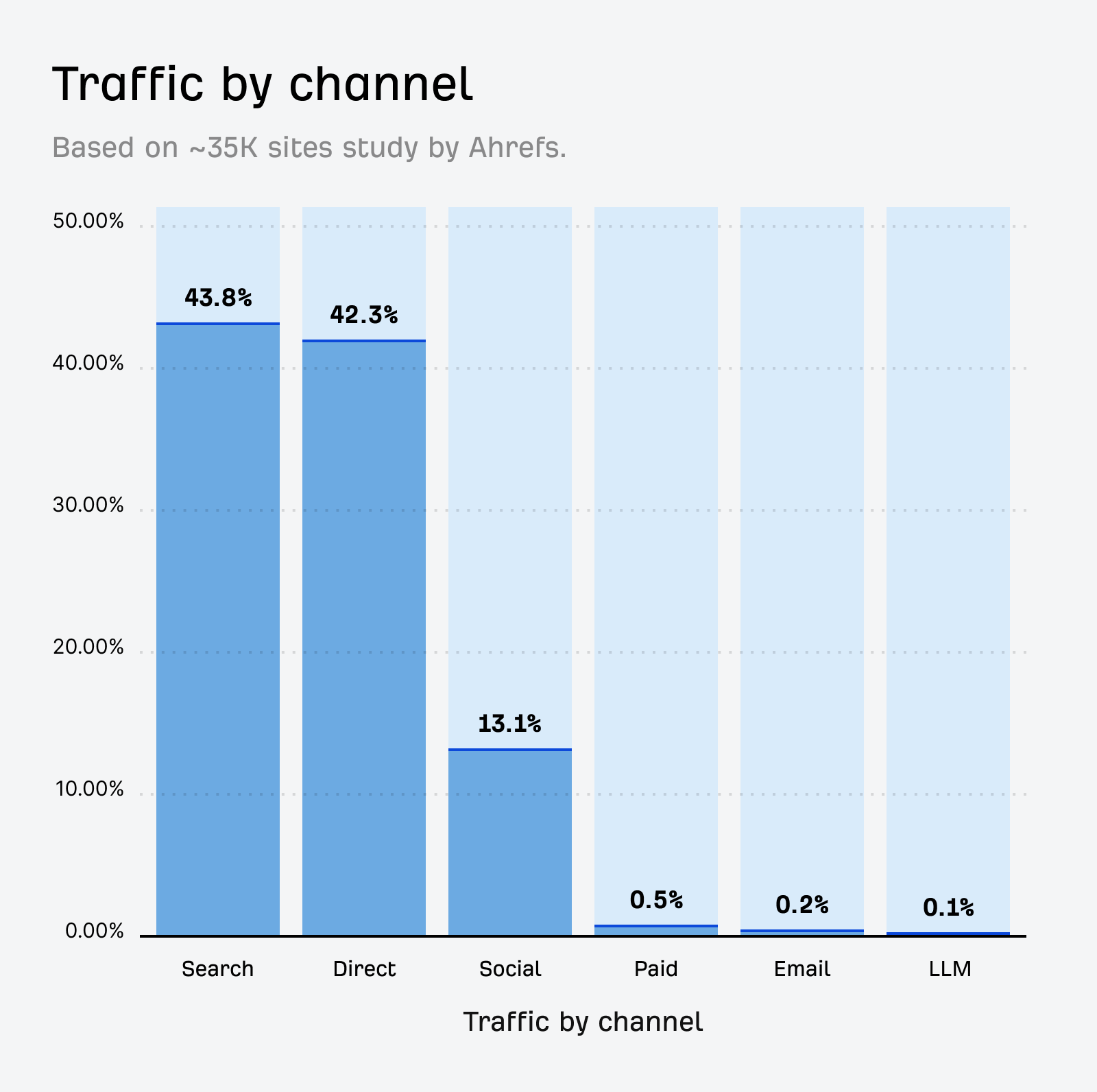
I think many site owners want to let these bots learn about their brand, their business, and their products and offerings. But while many people are betting that these systems are the future, they currently run the risk of not adding enough value for website owners.
The first LLM to add more value to users by showing impressions and clicks to website owners will likely have a big advantage. Companies will report on the metrics from that LLM, which will likely increase adoption and prevent more websites from blocking their bot.
The bots are using resources, using the data to train their AIs, and creating potential privacy issues. As a result, many websites are choosing to block AI bots.
We looked at ~140 million websites and our data shows that block rates for AI bots have increased significantly over the past year. I want to give a huge thanks to our data scientist Xibeijia Guan for pulling this data.

There is a moderate positive correlation between the request rate and the block rate for these bots. Bots that make more requests tend to be blocked more often. The nerdy numbers are 0.512 Pearson correlation coefficient, p-value of 0.0149, and this is statistically significant at the 5% level.
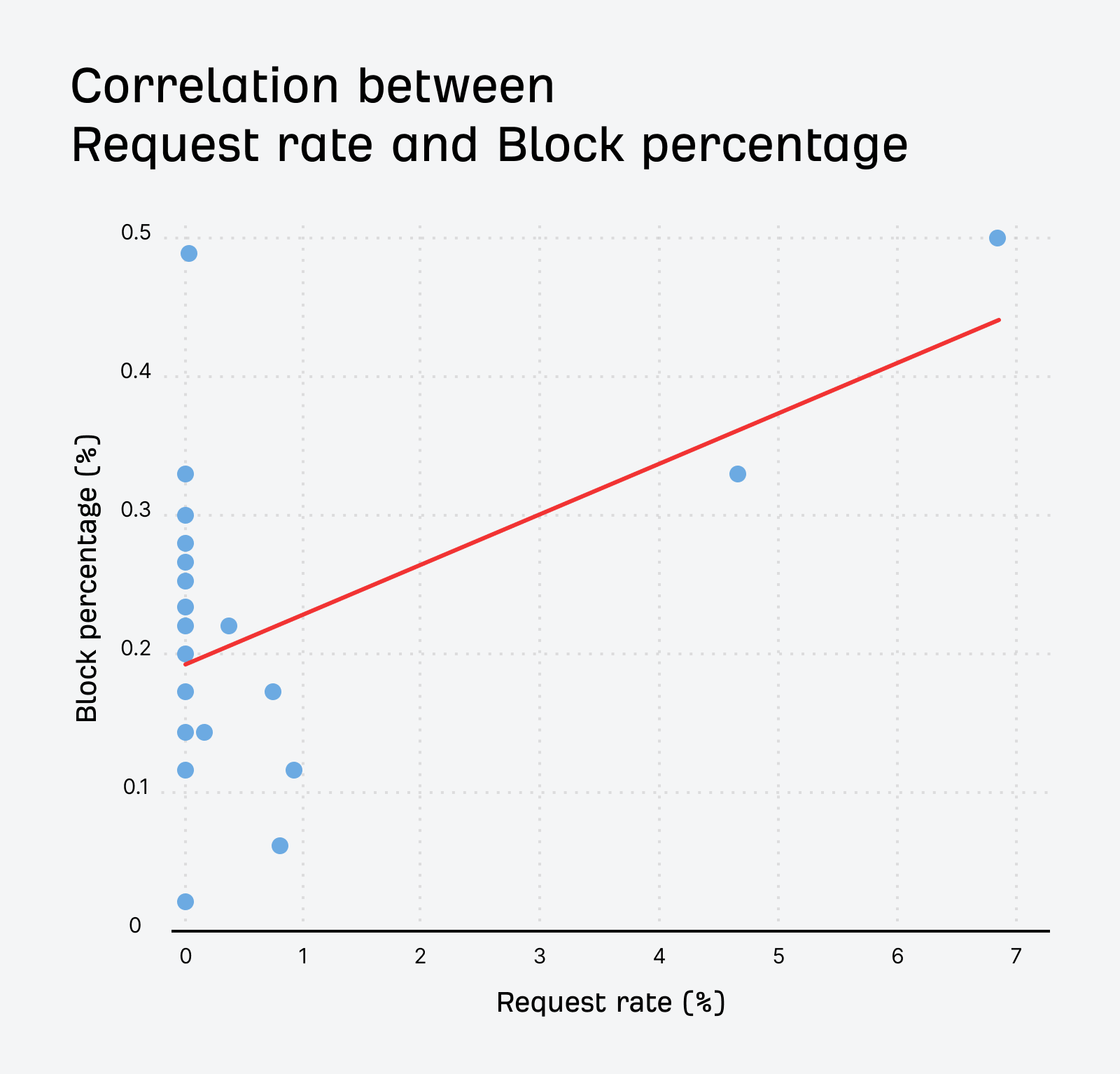
Here’s the data for the overall blocks:
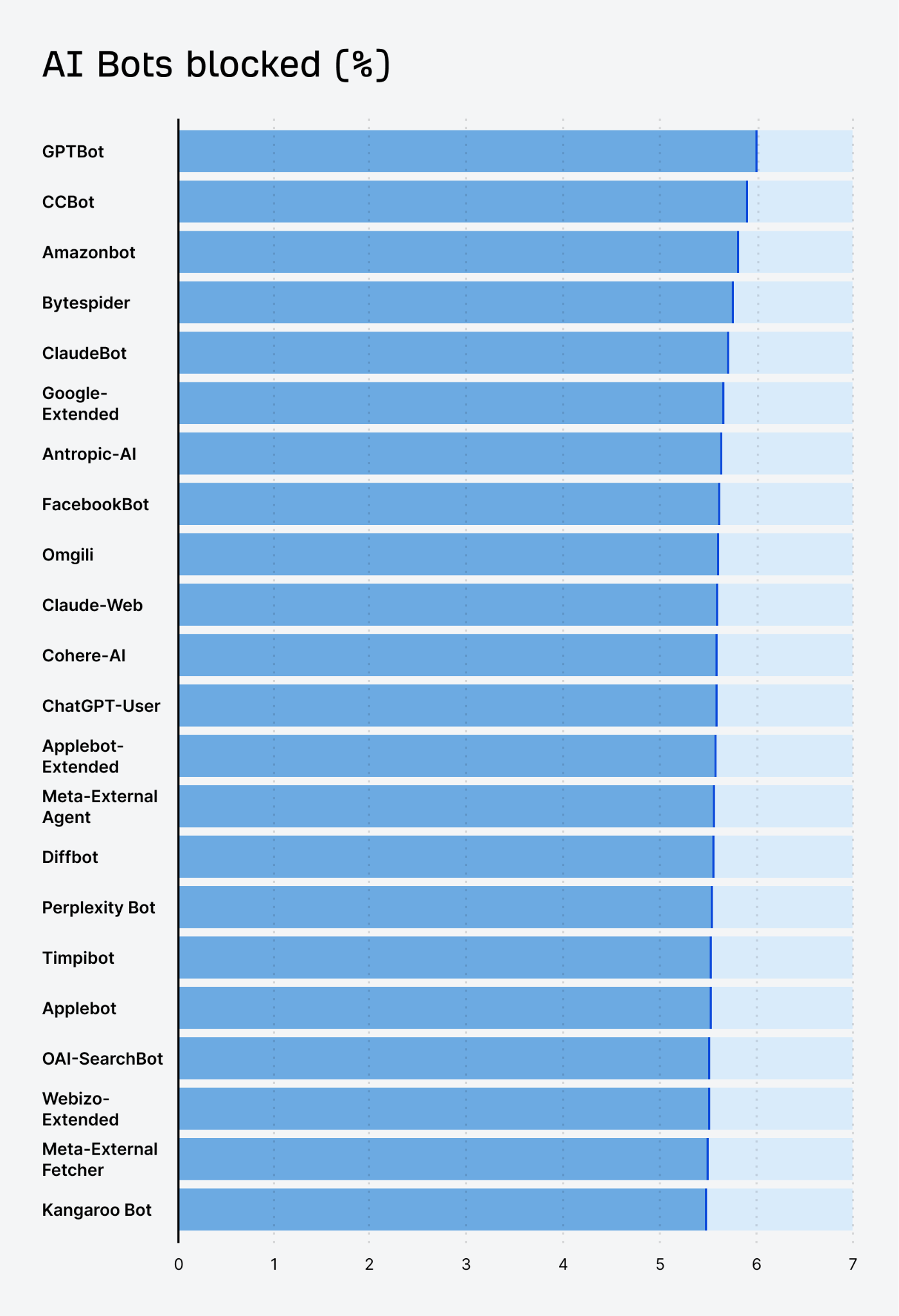
Here is the total number of websites blocking AI bots:
Here’s the data:
| Bot Name | Count | Percentage % | Bot Operator |
|---|---|---|---|
| GPTBot | 8245987 | 5.89 | OpenAI |
| CCBot | 8188656 | 5.85 | Common Crawl |
| Amazonbot | 8082636 | 5.78 | Amazon |
| Bytespider | 8024980 | 5.74 | ByteDance |
| ClaudeBot | 8023055 | 5.74 | Anthropic |
| Google-Extended | 7989344 | 5.71 | |
| anthropic-ai | 7963740 | 5.69 | Anthropic |
| FacebookBot | 7931812 | 5.67 | Meta |
| omgili | 7911471 | 5.66 | Webz.io |
| Claude-Web | 7909953 | 5.65 | Anthropic |
| cohere-ai | 7894417 | 5.64 | Cohere |
| ChatGPT-User | 7890973 | 5.64 | OpenAI |
| Applebot-Extended | 7888105 | 5.64 | Apple |
| Meta-ExternalAgent | 7886636 | 5.64 | Meta |
| Diffbot | 7855329 | 5.62 | Diffbot |
| PerplexityBot | 7844977 | 5.61 | Perplexity |
| Timpibot | 7818696 | 5.59 | Timpi |
| Applebot | 7768055 | 5.55 | Apple |
| OAI-SearchBot | 7753426 | 5.54 | OpenAI |
| Webzio-Extended | 7745014 | 5.54 | Webz.io |
| Meta-ExternalFetcher | 7744251 | 5.54 | Meta |
| Kangaroo Bot | 7739707 | 5.53 | Kangaroo LLM |
It gets a little more complicated. For the above, we looked at the main robots.txt file for a website, but every subdomain can have its own set of instructions. If we look at the ~461M robots.txt in total, then the total block % for GPTBot goes up to 7.3%.
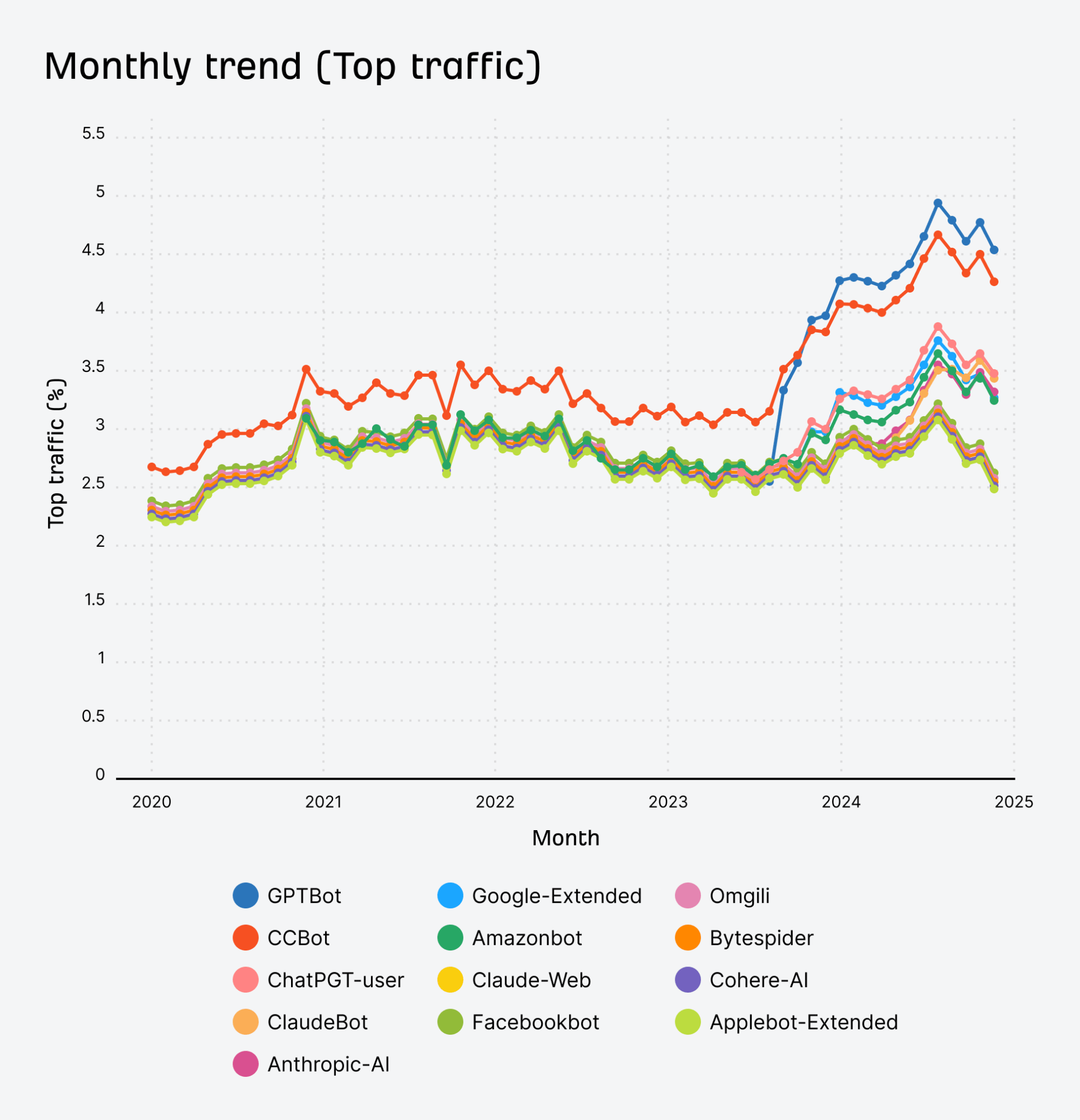
AI bot blocks over time
More top-trafficked sites began blocking AI bots in 2024, but the trend is decreasing towards the end of the year. It looks like the decrease mostly comes from generic blocks. The trend for AI bots themselves is increasing and I’ll show you that in a minute.
Do certain types of sites block AI bots more?
Here’s how it breaks down for each individual bot in different categories of websites. I was actually expecting news to be more blocked than other categories because there were a lot of stories about news sites blocking these bots, but arts & entertainment (45% blocked) and law & government (42% blocked) sites blocked them more.
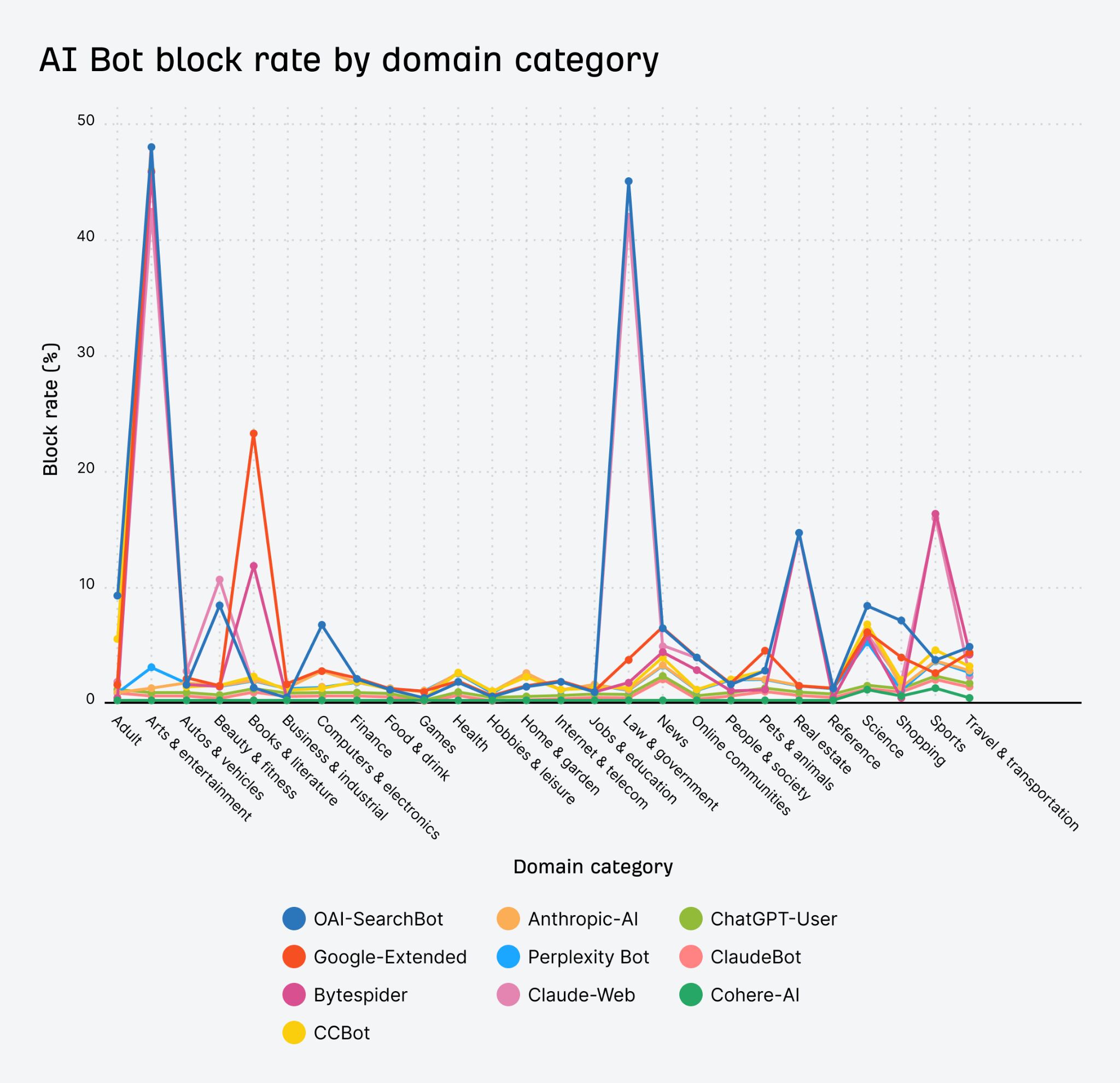
The decision to block AI bots varies by industry. There can be a number of unique reasons for this. These are somewhat speculative:
- Arts and Entertainment: ethical aversions, reluctance to become training data.
- Books and Literature: copyright.
- Law and Government: legal worries, compliance.
- News and Media: prevent their articles from being used to train AI models that could compete with their journalism and take away from their revenue.
- Shopping: prevent price scraping or inventory monitoring by competitors.
- Sports: similar to news and media on the revenue fears.
Similar Posts
PsiQuantum Secures $1B to Build Fault-Tolerant Million-Qubit Computers
Quantum computing start-up PsiQuantum has secured $1 billion in fresh funding to accelerate its ambitious plan…
AMD Unveils 5th Gen EPYC CPUs, Boosting Server Performance for AI and Cloud
AMD’s 5th Gen EPYC CPUs enhance server speed and efficiency significantly. These chips, utilizing the Zen…
Cisco and NTT DATA Partner to Modernize Networks for AI Era
NTT DATA and Cisco have announced a deepened collaboration aimed at reshaping enterprise networking for the…
Happy Thanksgiving! See you tomorrow?
Join me live Friday November 28: https://www.youtube.com/live/sxgBUE8ylm4?si=WEA_u665WBTpSrDa
Forget Semrush — I Tried 9 Best Semrush Alternatives for Bloggers
Semrush has always been my favorite go-to tool for SEO research. Unfortunately, it comes with a…
Crypto Security Expert Critiques Bitcoin Billionaires Advice
🚨 Watch my free crypto masterclass: https://youtu.be/fbut5dLecrs Here’s Jordan Welch’s video: https://youtu.be/arkn9rqczJ8?si=kSVicTANH5-n1E7_ Chapters:0:00 – The interviewees0:40…





