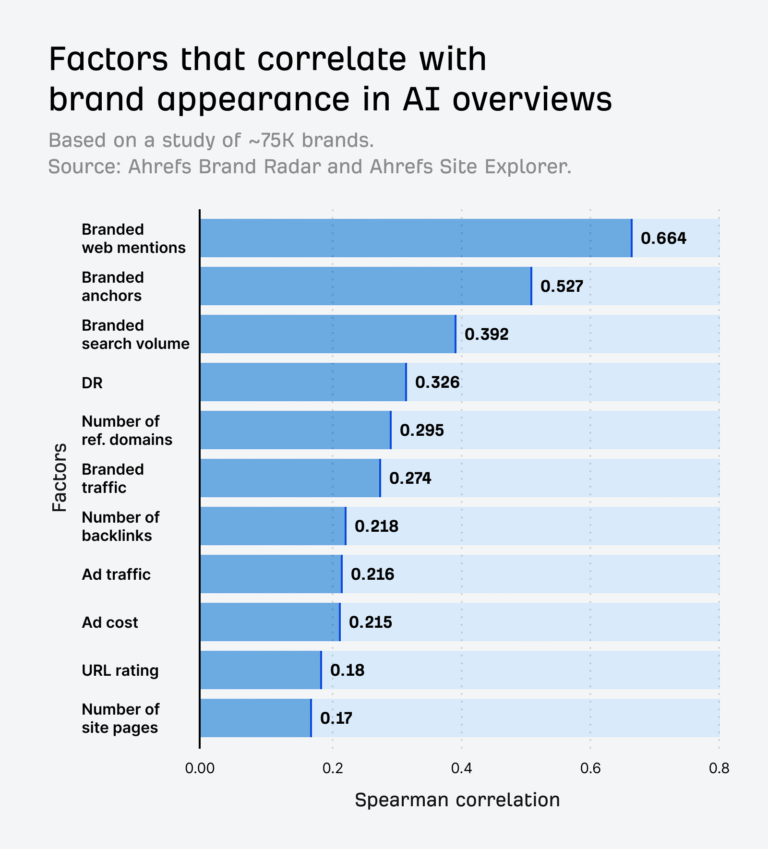
The digital landscape continues to expand as organizations seek actionable insights from publicly available web data. As web crawling becomes a core function in data collection and analysis, the importance of upholding data privacy and aligning with compliance frameworks has never been more pressing. Companies must strike a careful balance between harnessing the value of online information and respecting the boundaries set by legal requirements and ethical considerations.
Defining Data Privacy Compliance in Web Crawling
Data privacy compliance refers to the adherence to regional and international laws governing the collection, processing, and storage of personal or sensitive information. Regulations such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Personal Data (Privacy) Ordinance in Hong Kong are designed to protect individuals’ rights over their digital footprint. For web crawling operations, this means organizations must assess the type of data collected, ensure it is lawfully accessed, and implement safeguards around its use and storage.
Principles of Ethical Web Crawling
Ethical web crawling is built upon the foundation of transparency, respect, and accountability. It goes beyond technical execution and into the realm of corporate responsibility. Responsible organizations follow these principles:
- Respect for Website Terms: Ethical crawlers honor robots.txt directives and website terms of service, ensuring that only permitted resources are accessed.
- Minimization of Impact: Efficient crawling schedules and bandwidth management help reduce strain on target websites, demonstrating respect for digital infrastructure.
- Data Minimization: Only necessary data is collected, avoiding the gathering of personal or sensitive information unless there is a justifiable, lawful basis.
- Transparent Intent: Clearly articulating the purpose of data collection—especially when personal data is involved—builds trust and reduces legal risk.
Compliance Challenges in Web Crawling Activities
Web crawling intersects with a variety of compliance challenges, especially when operating across jurisdictions. Some of the most common considerations include:
- Jurisdictional Variations: Different regions impose varying requirements on data collection, consent, and user notification. Multinational organizations must be vigilant in understanding and applying the correct regulatory framework.
- Data Subject Rights: Laws such as GDPR grant individuals rights to access, rectify, and erase their data. Systems must be in place to honor these requests, even when data is collected via automated methods.
- Data Security: Collected data, particularly when sensitive, should be encrypted in transit and at rest. Access controls and audit logs help demonstrate compliance during regulatory reviews.
Why Dedicated Servers Are Essential for Compliance and Ethical Crawling
Dedicated servers provide the performance, security, and configurability needed to support compliant and ethical web crawling operations. By leveraging isolated hardware environments, organizations can:
- Implement Robust Security Protocols: Isolated environments allow for strict firewall controls, secure VPNs, and advanced DDoS protection, reducing the risk of data breaches.
- Optimize Resource Allocation: Dedicated resources ensure that crawling activities are efficient and do not inadvertently disrupt other digital services or networks.
- Support Regulatory Requirements: Hosting data within specific geographic boundaries becomes possible, assisting with data localization and sovereignty requirements that are common in privacy laws.
Providers like Dataplugs offer dedicated server solutions that cater to these demands. With infrastructure in Hong Kong and other global locations, Dataplugs enables organizations to choose server locations that align with both business needs and regulatory mandates. Their servers are designed with uptime, reliability, and advanced security in mind, which are crucial for maintaining continuous compliance.
Best Practices for Compliant and Ethical Web Crawling
Adhering to industry best practices is essential for any organization seeking to maintain compliance and ethical standards in web crawling, including:
- Continuous Monitoring: Regularly audit crawling scripts and data storage to ensure ongoing compliance with evolving laws.
- Consent Mechanisms: Where required, obtain explicit consent before collecting or processing personal data.
- Documentation: Keep records of data sources, crawling schedules, and compliance checks. This documentation supports transparency and regulatory audits.
- Collaboration with Legal Experts: Work closely with privacy professionals to interpret new regulations and adapt crawling practices accordingly.
Navigating the Legal Landscape: Key Global Regulations
Regulatory frameworks are evolving rapidly in response to growing concerns about privacy and data protection. The GDPR has set a precedent for stringent data privacy requirements, emphasizing informed consent, data minimization, and the right to be forgotten. The CCPA extends similar rights to California residents, while other regions like Hong Kong and Singapore maintain their own robust standards. Organizations engaging in web crawling should routinely review regulatory updates and perform regular gap analyses to ensure that practices remain compliant, especially when operating in multiple jurisdictions.
Technical Safeguards for Privacy-First Crawling
Implementing privacy-by-design principles is critical for maintaining compliance. Technical safeguards include using anonymization and pseudonymization techniques where possible, encrypting data both in transit and at rest, and deploying access controls to ensure that only authorized personnel interact with sensitive datasets. Moreover, rate limiting, IP rotation, and monitoring for abnormal activity can help prevent unintentional denial-of-service incidents and ensure respectful interaction with target sites.
Addressing the Ethics of Automated Data Collection
Beyond compliance, the ethics of automated data collection require careful consideration of the broader impact on stakeholders. Transparency about crawling activities, avoidance of collecting non-public or proprietary information, and engaging with website owners when necessary are all part of a responsible data strategy. Ethical web crawling also involves contributing to the community by reporting discovered vulnerabilities or errors, fostering a healthier digital ecosystem.
The Role of Infrastructure Partners in Supporting Compliance
Infrastructure partners play a pivotal role in enabling secure and compliant web crawling. Providers such as Dataplugs offer advanced security features, flexible server configurations, and expertise in data center compliance standards. Their support extends to rapid provisioning, 24/7 technical assistance, and customizable network configurations that help organizations respond swiftly to changing regulatory demands and scale their crawling operations without compromising privacy or security.
Conclusion
The intersection of data privacy, compliance, and web crawling is complex and dynamic. As organizations increasingly rely on automated data collection for competitive advantage, the need to align with ethical standards and regulatory frameworks is paramount. Dedicated servers, such as those offered by Dataplugs, provide the secure and customizable infrastructure foundation needed to support ethical web crawling and robust compliance programs. By focusing on transparency, minimizing impact, and embracing best practices, organizations can unlock the value of web data while safeguarding privacy and maintaining public trust. To discuss tailored infrastructure solutions or receive expert advice on compliant web crawling, reach out to Dataplugs via live chat or email sales@dataplugs.com.