Developers and marketers are being told to add llms.txt files to their sites to help large language models (LLMs) “understand” their content.
But what exactly is llms.txt, who’s using it, and—more importantly—should you care?
In a nutshell, it’s a text file designed to tell LLMs where to find the good stuff: API documentation, return policies, product taxonomies, and other context-rich resources. The goal is to remove ambiguity by giving language models a curated map of high-value content, so they don’t have to guess what matters.
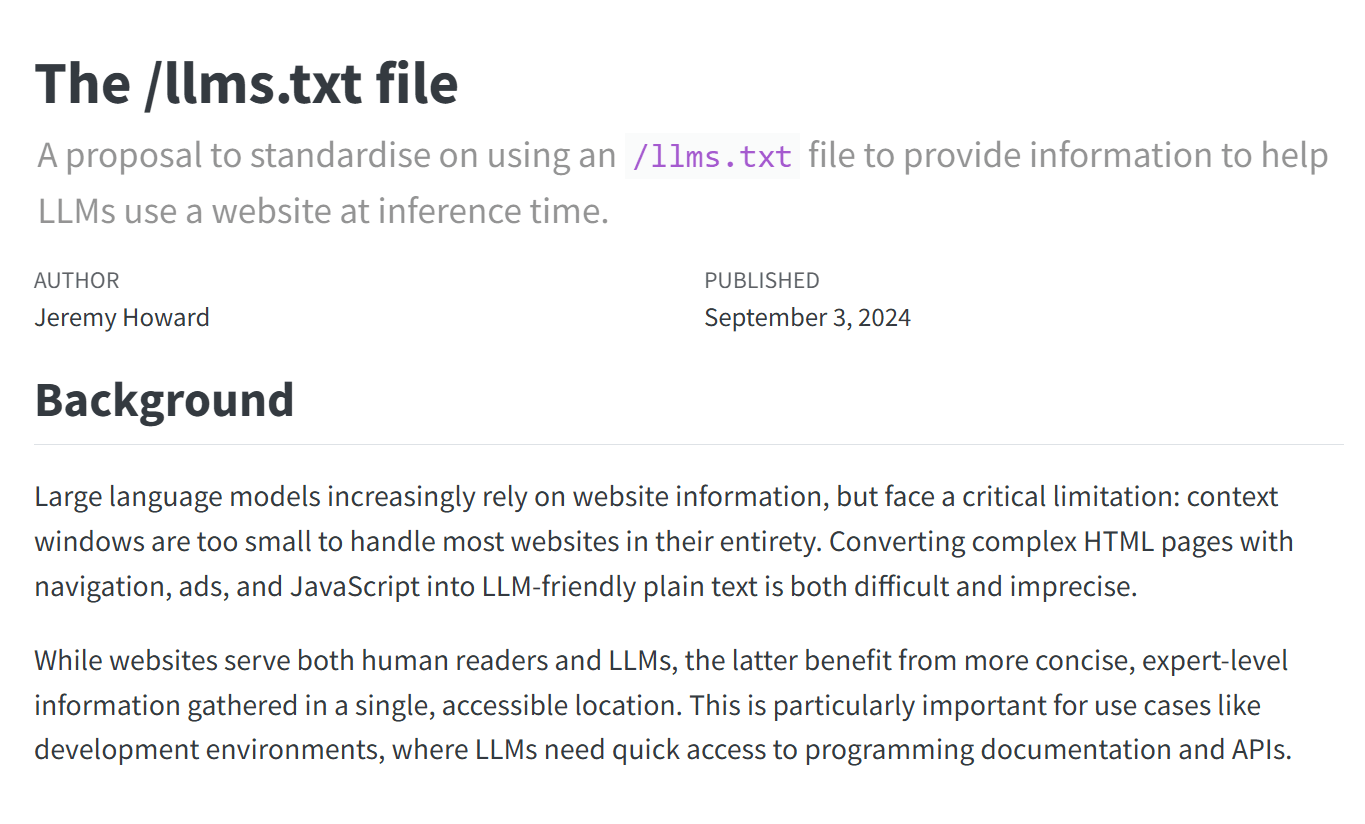
A screenshot from the proposed standard over on https://llmstxt.org/.
In theory, this sounds like a good idea. We already use files like robots.txt and sitemap.xml to help search engines understand what’s on a site and where to look. Why not apply the same logic to LLMs?
But importantly, no major LLM provider currently supports llms.txt. Not OpenAI. Not Anthropic. Not Google.
As I said in the intro, llms.txt is a proposed standard. I could also propose a standard (let’s call it please-send-me-traffic-robot-overlords.txt), but unless the major LLM providers agree to use it, it’s pretty meaningless.
That’s where we’re at with llms.txt: it’s a speculative idea with no official adoption.
Don’t sleep on robots.txt
llms.txt might not impact your visibility online, but robots.txt definitely does.
You can use Ahrefs’ Site Audit to monitor hundreds of common technical SEO issues, including problems with your robots.txt file that might seriously hamper your visibility (or even stop your site from being crawled).
At its core, llms.txt is a Markdown document (a kind of specially formatted text file). It uses H2 headers to organize links to key resources. Here’s a sample structure you could use:
# llms.txt ## Docs - /api.md A summary of API methods, authentication, rate limits, and example requests. - /quickstart.md A setup guide to help developers start using the platform quickly. ## Policies - /terms.md Legal terms outlining service usage. - /returns.md Information about return eligibility and processing. ## Products - /catalog.md A structured index of product categories, SKUs, and metadata. - /sizing-guide.md A reference guide for product sizing across categories.
You can make your own llms.txt in minutes:
- Start with a basic Markdown file.
- Use H2s to group resources by type.
- Link to structured, markdown-friendly content.
- Keep it updated.
- Host it at your root domain: https://yourdomain.com/llms.txt
You can create it yourself or use a free llms.txt generator (like this one) to make it for you.
I’ve read about some developers also experimenting with LLM-specific metadata in their llms.txt files, like token budgets or preferred file formats (but there’s no evidence that this is respected by crawlers or LLM models).
Here are a few examples:
- Mintlify: Developer documentation platform.
- Tinybird: Real-time data APIs.
- Cloudflare: Lists performance and security docs.
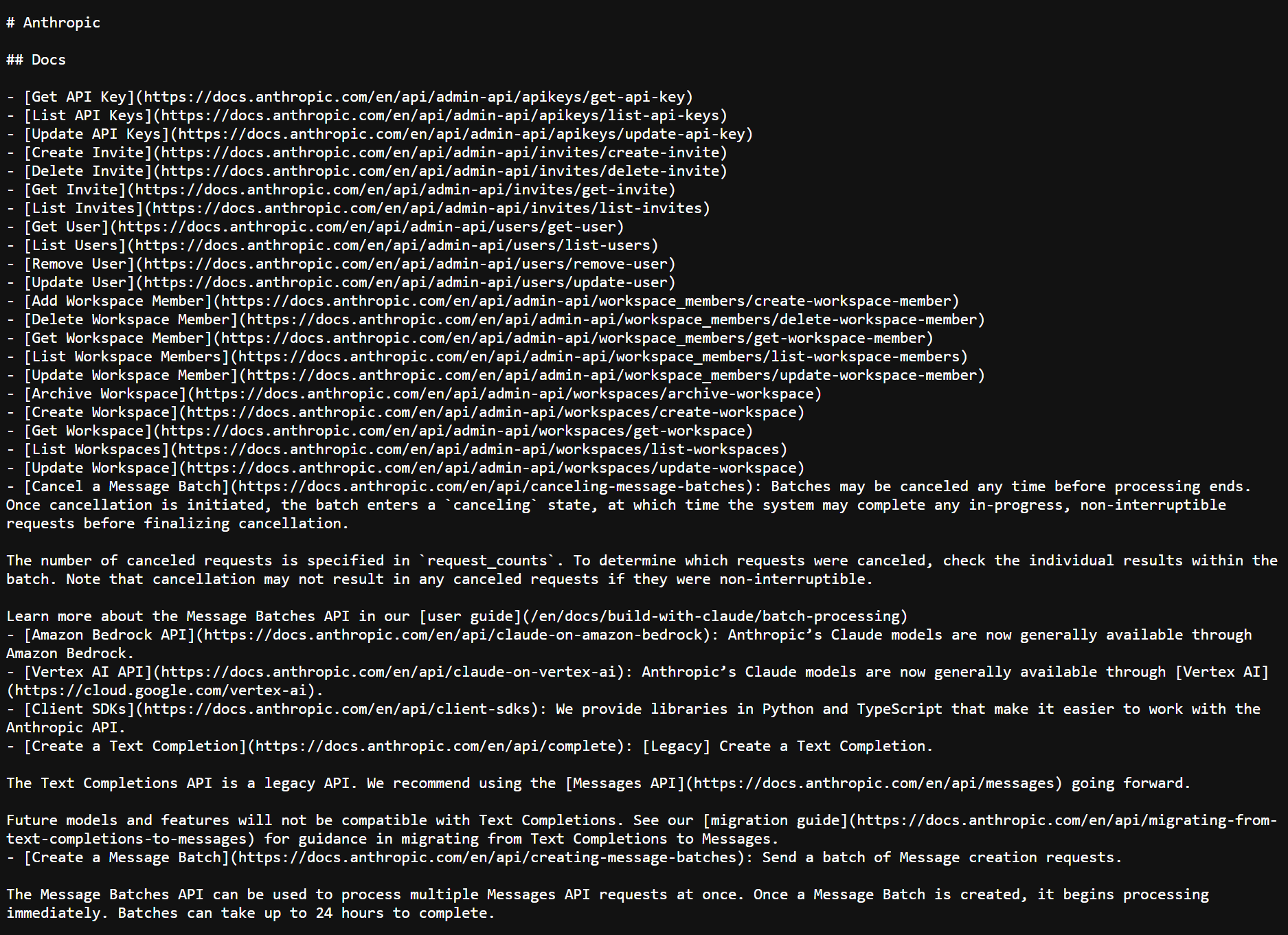
- Anthropic: Publishes a full Markdown map of its API docs.
But what about the big players?
So far, no major LLM provider has formally adopted llms.txt as part of their crawler protocol:
- OpenAI (GPTBot): Honors robots.txt but doesn’t officially use llms.txt.
- Anthropic (Claude): Publishes its own llms.txt, but doesn’t state that its crawlers use the standard.
- Google (Gemini/Bard): Uses robots.txt (via User-agent: Google-Extended) to manage AI crawl behavior, with no mention of llms.txt support.
- Meta (LLaMA): No public crawler or guidance, and no indication of llms.txt usage.
This highlights an important point: creating an llms.txt is not the same as enforcing it in crawler behavior. Right now, most LLM vendors treat llms.txt as an interesting idea, and not something that they’ve agreed to prioritize and follow.
But in my personal view, llms.txt is a solution in search of a problem. Search engines already crawl and understand your content using existing standards like robots.txt and sitemap.xml. LLMs use much of the same infrastructure.
As Google’s John Mueller put it in a Reddit post recently:
AFAIK none of the AI services have said they’re using LLMs.TXT (and you can tell when you look at your server logs that they don’t even check for it). To me, it’s comparable to the keywords meta tag – this is what a site-owner claims their site is about … (Is the site really like that? well, you can check it. At that point, why not just check the site directly?)

Disagree with me, or want to share an example to the contrary? Message me on LinkedIn or X.
Further reading
Similar Posts
What Is the Difference Between Committed Bandwidth and Burst Bandwidth?
Network performance challenges rarely come from raw bandwidth limitations alone. In many cases, the underlying issue…
Tangem Wallet Q&A + BIG Tangem Pay Update!
🚨 Get 15% OFF your entire Tangem order with this link: https://tangem.com/en/pricing/?promocode=CYBERSCRILLA#pricing Or use my code…
Digi Power X, Supermicro Deploy B200 GPUs in Alabama Data Center
Digi Power X, a vertically integrated power infrastructure company specializing in high-performance computing (HPC) data centers,…
VMware Cloud Foundation: Patching Failed
VCF February 7, 2024 VMware Cloud Foundation: Patching Failed SDDC Manager: Unable To Configure Security Global…
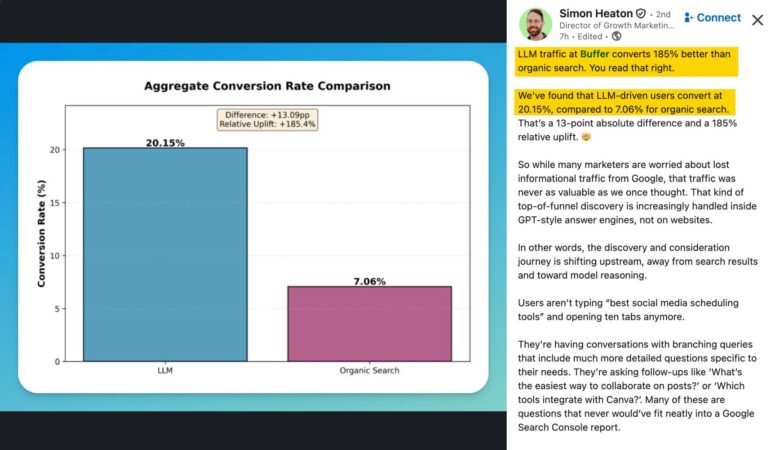
The ChatGPT Traffic Playbook: How to Track, Measure, and Grow
In October 2025, ChatGPT had more than 800 million weekly users; yet, most analytics dashboards don’t…
I Tried 7 Best GoFundMe Alternatives (Raise More, Pay Less)
You shouldn’t have to lose control of your donor data and rely on a third-party platform…