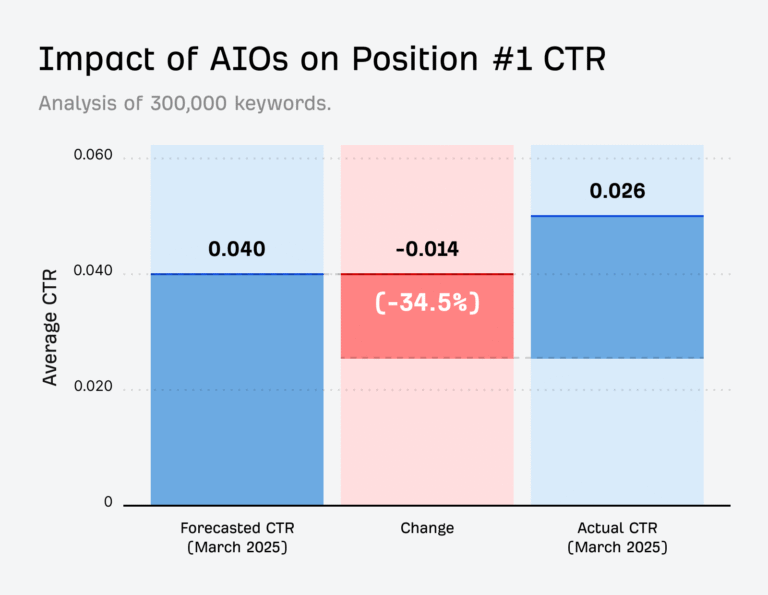
Effective AI infrastructure depends on a balanced architecture in which compute, memory, storage, and networking operate as a tightly integrated whole. Without that balance, even the most powerful accelerators can sit idle, starved of data or constrained by bandwidth limitations.
The rise of AI-accelerated servers is inseparable from the dominance of GPUs in modern machine learning. Unlike CPUs, which excel at sequential processing, GPUs are optimized for parallel computation, making them uniquely suited for tensor operations and matrix multiplications that underpin neural networks. This architectural advantage has made GPUs the default engine for training and inference across deep learning workloads.
Demand for GPU capacity has surged as model sizes grow and inference moves closer to end users. Data center-class accelerators such as the NVIDIA H100 are now widely viewed as essential for large-scale training, while GPUs from the RTX family are commonly deployed for inference and fine-tuning where cost efficiency matters. As a result, access to GPUs has become a strategic consideration rather than a purely technical one.
Why AI Servers Require More Than GPUs
Enterprises deploying AI workloads are learning that GPU performance alone does not guarantee results. The surrounding system architecture determines whether accelerators can operate at full capacity. CPUs with a high number of PCIe lanes are critical for feeding data efficiently to multiple GPUs, preventing throughput bottlenecks.
Memory capacity is equally important, as large datasets must be staged in RAM before processing. In many production environments, 256 GB or more of ECC memory is becoming a baseline rather than a luxury.
Storage performance also plays a decisive role. NVMe-based solid-state drives have emerged as a requirement for AI servers, significantly reducing data loading times compared to legacy SATA SSDs. Faster storage directly translates into shorter training cycles and improved utilization of expensive GPU resources. Meanwhile, high-bandwidth, low-latency networking – often 10 Gbps or higher – is essential for distributed training, model serving, and integration with external data sources.
Why GPUs Matter More Than Ever for AI
The growing reliance on GPUs reflects three fundamental realities of modern AI workloads. First, parallelism is intrinsic to deep learning. GPUs can execute thousands of operations simultaneously, enabling training times that are often an order of magnitude faster than CPU-only systems. Second, AI pipelines increasingly span training, fine-tuning, and inference, all of which benefit from acceleration. Third, emerging use cases – from large language models and image generation to reinforcement learning – are computationally infeasible without GPU-class hardware.
As AI moves into latency-sensitive domains such as fraud detection, conversational interfaces, and real-time personalization, inference performance has become just as critical as training speed. Enterprises now evaluate GPU infrastructure not only on raw throughput but also on consistency, energy efficiency, and predictability under load.
Understanding GPU Server Deployment Models
Organizations can access GPU computing through several distinct models, each with trade-offs that reflect different business priorities. Public cloud platforms offer on-demand GPU instances that eliminate upfront investment and enable rapid scaling. These environments are well suited to experimentation, short-term projects, and bursty workloads, but costs can escalate quickly for sustained usage.
Dedicated GPU instances address some of these concerns by reserving capacity over longer periods, providing predictable performance and pricing. For production AI services that cannot tolerate resource contention or availability risks, this model is increasingly popular.
Bare-metal GPU servers represent the opposite end of the spectrum, offering full control over hardware and software stacks without virtualization overhead. They are favored by organizations running performance-critical training workloads or highly customized AI frameworks, though they require greater operational expertise.
Hybrid and on-premises GPU clusters combine local infrastructure with cloud elasticity, allowing enterprises to retain control over sensitive data while scaling compute when needed. This approach is particularly common in regulated industries such as healthcare, finance, and government, where data sovereignty and compliance requirements influence architectural decisions.
Matching Infrastructure Choices to AI Workloads
Selecting the right AI server strategy depends on aligning infrastructure with workload characteristics. Training large models demands high-memory GPUs, fast interconnects, and scalable architectures, while inference often prioritizes efficiency and low latency. Budget models also vary, with cloud-based approaches favoring operational expenditure and on-premises deployments requiring capital investment but offering long-term cost stability.
Latency considerations further complicate the picture. Applications such as autonomous systems or high-frequency trading may require GPUs close to data sources or end users, making edge or on-premises deployments more attractive. Regulatory constraints around data location can also dictate architectural choices, reinforcing the appeal of hybrid models.
The Strategic Role of AI-Accelerated Servers
As AI adoption matures, AI-accelerated servers are increasingly viewed as foundational infrastructure rather than specialized tools. Decisions about GPU access models now influence time-to-market, operating costs, and competitive differentiation. Enterprises that treat AI infrastructure as a strategic asset – rather than an afterthought – are better positioned to scale models responsibly and efficiently.
In this environment, the question is no longer whether AI requires specialized servers, but how organizations can architect those systems to balance performance, cost, and control over the long term.
Executive Insights FAQ
What defines an AI-accelerated server compared to a traditional server?
An AI-accelerated server is a balanced high-performance system designed to eliminate bottlenecks across compute, memory, storage, and networking, with GPUs at its core.
Why are GPUs essential for modern AI workloads?
GPUs excel at parallel processing, enabling faster training, fine-tuning, and inference for deep learning models compared to CPU-based systems.
How do enterprises typically access GPU computing today?
Organizations use a mix of cloud GPU instances, dedicated GPU services, bare-metal servers, and hybrid or on-premises clusters depending on workload and compliance needs.
What role does storage and networking play in AI performance?
Fast NVMe storage and high-bandwidth networking ensure GPUs remain fully utilized, reducing training times and improving inference responsiveness.
How should businesses choose the right AI server model?
The decision depends on workload type, budget model, latency requirements, and regulatory constraints, with no single approach fitting all use cases.